نصب و راه اندازی
اهداف
- در این آموزش نحوه نصب و راه اندازی این کتابخانه را یادمیگیریم
نصب کتابخانه های مورد نیاز
- بسته های زیر باید در محل پیش فرض نصب شوند Python 3.x (3.4+) یا Python 2.7.x از اینجا
-
نصب Numpy
pip install numpy -
نصب matplotlib
pip install matplotlib -
نصب open-cv
pip install opencv-python
شروع به کار با عکس ها
اهداف
- خواندن عکس از فایل
- نمایش دادن عکس در یک صفحه
- نوشتن یک عکس داخل فایل
کد
import cv2 as cv
import sys
img = cv.imread(cv.samples.findFile("starry_night.jpg"))
if img is None:
sys.exit("Could not read the image.")
cv.imshow("Display window", img)
k = cv.waitKey(0)
if k == ord("s"):
cv.imwrite("starry_night.png", img)
توضیحات
در مرحله اول کتابخانه مورد نظر را تعریف می کنیم.
import cv2 as cv
import sys
حالا نوبت تحلیل کد اصلی است.در مرحله اول عکس "starry_Night.png" را از نمونه های کتابخانه میخوانیم.
صدا زدن cv::imread دو ورودی میگیرد که اولین ورودی آدرس عکس است.
ورودی دوم اختیاری است که کار مشخص کردن فرمت عکس را انجام میدهد.
ورودی های دوم:
cv.IMREAD_COLOR: عکس را در فرمت BGR 8-bit بارگذاری میکندcv.IMREAD_UNCHANGEDcv.IMREAD_GRAYSCALE: بارگذاری عکس به صورت شدتی(سفید و سیاه)
بعد از خوانده شدن عکس , اطلاعات در یک آبجکت cv::Mat ذخیره میشود.
img = cv.imread(cv.samples.findFile("starry_night.jpg"))
در ادامه یک تست اجرا میشود تا بارگذاری صحیح عکس آزموده شود.
if img is None:
sys.exit("Could not read the image.")
سپس عکس توسط تابع cv::imshow نمایش داده میشود.
این تابع 2 ورودی دارد که اولین ورودی آن عنوان پنجره ای است که عکس در آن نمایش داده میشود و دومین ورودی آن آبجکت cv::Mat است.
برای اینکه صفحه را تا زمانی که کاربر کلیدی را وارد کند نمایش دهیم از تابع cv::waitkey استفاده میکنیم.
این تابع یک ورودی دارد که نشان دهنده مدت زمانیست که برنامه باید برای ورودی کاربر صبر کند.
ورودی تابع int است و به میلی ثانیه هستند.
صفر نشان دهنده این است که برنامه باید برای همیشه صبر کند.
به عنوان مثال اگر عدد 5000 رابه تابع بدهیم
cv.waitkey(5000) به مدت 5 ثانیه صبر میکند
واحد میلی ثانیه است.
اگر عدد صفر به تابع داده شود برای همیشه صبر میکند برای همین بهتر است از cv.destroyAllWindows بعد از cv.waitkey(0) استفاده شود.
cv.imshow("Display window", img)
k = cv.waitKey(0)
در نهایت برنامه درصورتی که کلید s فشرده شود عکس را در یک فایل ذخیره میکند.
این عمل توسط تابع cv::imwrite انجام میشود که 2 ورودی دارد.
یک ورودی مسیر ذخیره فایل و ورودی دیگر یک آبجکت cv::Mat
if k == ord("s"):
cv.imwrite("starry_night.png", img)
اگر با عکس هایی با کیفیت بالا استفاده میکنید میتوانید با استفاده از cv.resize() کیفیت عکس را تغییر دهید
import cv2 as cv
import sys
# خواندن تصویر
img = cv.imread(cv.samples.findFile("starry_night.jpg"))
# بررسی اینکه آیا تصویر با موفقیت بارگذاری شده است
if img is None:
sys.exit("Could not read the image.")
# تغییر اندازه تصویر به ابعاد جدید (مثلاً نصف اندازه اصلی)
width = int(img.shape[1] * 0.5) # عرض تصویر جدید (50٪ از عرض اصلی)
height = int(img.shape[0] * 0.5) # ارتفاع تصویر جدید (50٪ از ارتفاع اصلی)
new_size = (width, height)
# تغییر اندازه تصویر
resized_img = cv.resize(img, new_size, interpolation=cv.INTER_LINEAR)
# نمایش تصویر اصلی و تصویر تغییر اندازه یافته
cv.imshow("Original Image", img)
cv.imshow("Resized Image", resized_img)
# منتظر بماند تا کاربر کلیدی را بفشارد
cv.waitKey(0)
# بستن همه پنجرهها
cv.destroyAllWindows()
تابع cv.resize() سه ورودی میگیرد
اولین ورودی عکس اصلی و دومین ورودی یک تاپل که به صورت (عرض , ارتفاع) است داده میشود
سومین ورودی روش درونیابی است که در اینجا از cv.INTER_LINEAR استفاده کردیم.
روش درون یابی در اصل همان روشی است که کمک میکند هنگام تغییر سایزی پیکسل های جدید کم و زیاد شوند
مطالعه بقیه روش ها به عهده خودتون.
شروع به کار با ویدیو
اهداف
- یادگیری خواندن و نوشتن و ذخیره ویدیو.
- یادگیری گرفتن تصویر از دوربین و ذخیره آن به صورت ویدیو.
- یادگیری توابع
cv.VideoCapture()وcv.VideoWriter()
دریافت ویدیو از دوربین
ما معمولا با گرفتن تصاویر از یک جریان ویدیو کار داریم.این کتابخانه یک محیط ساده برای اینکار فراهم کرده.بیاید شروع کنیم.
میخواهیم جریان تصویر رو از دوربین ریافت کنیم و اون رو به صورت یک ویدیو شدتی(سفید و سیاه) نشان دهیم
برای گرفتن ویدیو نیاز داریم یک آبجکت VideoCapture بسازیم.
ورودی های آن میتواند نام فایل یا ایندکس وسیله گیرنده ویدیو باشد.
ایندکس یک وسیله گیرنده مانند دوربین فقط عددی است که به آن وسیله تخصیص داده شده.
معمولا به لپتاپ یا کامپیوتر ما یک وسیله وصل است به همین دلیل من اینجا عدد 0 (یا1) رو وارد میکنم.
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# if frame is read correctly ret is True
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
# Our operations on the frame come here
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# Display the resulting frame
cv.imshow('frame', gray)
if cv.waitKey(1) == ord('q'):
break
# When everything done, release the capture
cap.release()
cv.destroyAllWindows()
cap.read مقادیر True یا False رو بر میگردوند که نشون دهنده اینه که آیا فریم ها به درستی خوانده میشوند یا خیر.
با این مقدار برگشتی میتونید بفهمید به آخر ویدیو رسیدهاید یا خیر.
بعضی مواقع ممکن است cap گیرنده ویدیو رو به اجرا در نیاورده باشد.
شما میتوانید با استفاده از cap.isOpened() این موضوع رو چک کنید . این تابع مقادیر True یا False رو بر میگردوند.
اگر False رو برگدوند میتواند با استفاده از cap.open() گیرنده رو به اجرا درآورید.
همچنین شما به میتوانید به بعضی از ویژگی های ویدیو توسط تابع cap.get(n) دسترسی داشته باشید که n عددی است از 0 تا 18 و
هر عدد به یک ویژگی ارتباط دارد.
اطلاعات کامل آن توسط تابع ()cv::VideoCapture::get قابل مشاهده است.
همچنین بعضی از این مقادیر توسط تابع cap.set(n, value) قابل تغییر هستند. value مقدار دلخواهی شما است که میخواهد ویژگی مربوط به n آن را تغییر دهید.
به عنوان مثال میتوانیم ارتفاع و عرض فریم رو با دستور cap.get(cv.CAP_PROP_FRAME_WIDTH) و cap.get(cv.CAP_PROP_FRAME_HEIGHT) مشاهده کنیم.
درحالت پیشفرض مقدار 640x480 داده میشود.
اما میخواهم این مقدار را به 320x240 تغییر دهم. برای این کار از دستور ret = cap.set(cv.CAP_PROP_FRAME_WIDTH,320)و ret = cap.set(cv.CAP_PROP_FRAME_HEIGHT,240) استفاده میکنم.
- اگر خطا دریافت میکنید مطمئن شوید دوربین دستگاه به درستی کار میکند.
پخش ویدیو از یک فایل
پخش کردن ویدیو مانند گرفتن ویدیو است با این تغییر که به جای شماره دستگاه دریافت کنند باید نام فایل رو وارد کنید.
همچنین هنگام پخش ویدیو از مقدار مناسبی برای cv.waitKey() استفاده کنید.
اگر کوچک باشد ویدیو خیلی سریع پخش میشود و اگر بزرگ باشید ویدیو خیلی کند پخش میشود
عدد 25 برای حالت عادی مناسب است.
import numpy as np
import cv2 as cv
cap = cv.VideoCapture('vtest.avi')
while cap.isOpened():
ret, frame = cap.read()
# if frame is read correctly ret is True
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
cv.imshow('frame', gray)
if cv.waitKey(1) == ord('q'):
break
cap.release()
cv.destroyAllWindows()
- مطمئن شوید که
ffmpegیاgstreamerبه درستی روی سیستم شما نصب شده باشد , درغیر اینصورت در کارکردن با این کتابخانه به مشکل خواهید خورد.
ذخیره ویدیو
خب تا اینجا ما ویدیو رو گرفتیم و فریم به فریم پردازش روی اون انجام دادیم و حالا میخواهیم اون رو ذخیره کنیم.
برای عکس ها خیلی راحت است و از دستور ()cv.imwrite استفاده میکنیم.
اما برای ویدیو یکم بیشتر کار داریم.
در اینجا یک آبجکت VideoWriter میسازیم. باید نام فایل خروجی را مشخص کنیم.
سپس باید کدک FourCC رو مشخص کنیم.
سپس باید FPS و اندازه هر فریم رو تنظیم کنیم.
درآخر باید isColor رو تنظیم کنیم. اگر True باشد انتظار یک فیلم رنگی و اگر False باشد انتظار یک ویدیو سفید و سیاه رو داریم.
FourCC یک مقدار 4 بایتی است که برای مشخص کردن کدک ویدیو به کار میرود. لیست کدک های موجود در fourcc.org است.
FourCC توسط cv.VideoWriter_fourcc('M’,'J','P','G') یا cv.VideoWriter_fourcc(*'MJPG') برای mjpg استفاده میشود.
کد زیر هر فریم رو دریافت میکنید و اون رو از عمودی به افقی تغییر میدهد و ذخیره میکند.
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(0)
# Define the codec and create VideoWriter object
fourcc = cv.VideoWriter_fourcc(*'XVID')
out = cv.VideoWriter('output.avi', fourcc, 20.0, (640, 480))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
frame = cv.flip(frame, 0)
# write the flipped frame
out.write(frame)
cv.imshow('frame', frame)
if cv.waitKey(1) == ord('q'):
break
# Release everything if job is finished
cap.release()
out.release()
cv.destroyAllWindows()
اهداف
- یادگیری ترسیم انواع شکل های هندسی
- یادگیری توابع
cv.line(), cv.circle() , cv.rectangle(), cv.ellipse(), cv.putText()
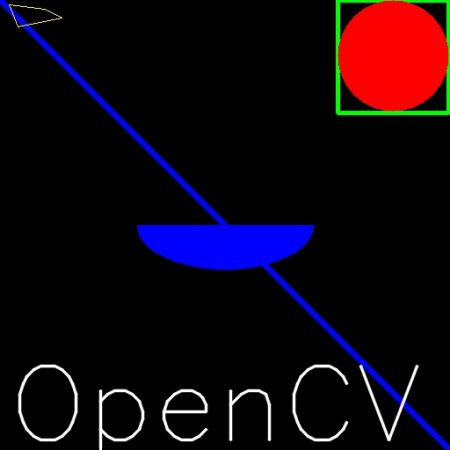
کد
همه توابعی که در نمونه کد خواهیم دید همه ورودی های مشترکی خواهند داشت
img : عکسی که در آن میخواهیم چیزی را رسم کنیم.
color : رنگ اشکل ها. برای RGB کافیست یک تاپل به عنوان ورودی دهیم به عنوان مثال (255,0,0) برای آبی و برای .
thickness : ضخامت هر خط یا دایره و ... اگر برای اشکال بسته مانند دایر عدد -1 به عنوان ورودی داده شود داخل شکل پر خواهد شد . ورودی پیش فرض : -1
lineType : نوع خط مانند 8-connected پیش فرض : 8-connected. cv.LINE_AA برای منحنی ها گزینه خوبی است
رسم خط
برای رسم خط باید مختصات ابتدا و انتهای خط داده شود. برای رسم یک خط آبی در صفحه مشکی که از بالا چپ به راست پایین است اینگونه عمل میکنیم.
import numpy as np
import cv2 as cv
# Create a black image
img = np.zeros((512,512,3), np.uint8)
# Draw a diagonal blue line with thickness of 5 px
cv.line(img,(0,0),(511,511),(255,0,0),5)
رسم مستطیل
برای رسم مستطیل نیاز به مختصات بالا چپ و پایین راست مستطیل داریم. این دفعه یک مسطیل سبز رسم میکنیم.
cv.rectangle(img,(384,0),(510,128),(0,255,0),3)
رسم دایره
برای رسم دایره نیاز به شعاع و مختصات مرکز داریم.
cv.circle(img,(447,63), 63, (0,0,255), -1)
رسم بیضی
برای رسم بیضی نیاز به چند ورودی داریم
- مختصات مرکز به صورت (x,y)
- طول قطر های بیضی
- زاویه چرخش بیضی در خلاف جهت عقربه های ساعت , زاویه شروع و پایان نشان دهنده شروع و پایان کمان بیضی است که در جهت عقربه های ساعت از محور اصلی اندازه گیری می شود. دادن مقادیر 0 و 360 نشان دهند بیضی کامل است. کد زیر نیمه بیضی در مرکز تصویر رسم میکند.
cv.ellipse(img,(256,256),(100,50),0,0,180,255,-1)
رسم چند ضلعی
برای رسم چند ضلعی به مختصات رئوس نیاز داریم. آن نقاط را به آرایه ای به شکل ROWSx1x2 تبدیل میکنیم به صورتی که ROWS تعداد رئوس را نشان میدهد و باید به صورت int32 باشد. یک نمومنه چد ضلعی زرد رنگ :
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
pts = pts.reshape((-1,1,2))
cv.polylines(img,[pts],True,(0,255,255))
اضافه کردن نوشته به عکس
برای قرارد دادن نوشته روی عکس نیاز به :
- نوشته مورد نظر
- مختصات مورد نظر که میخواهیم نوشته را روی آن قرار دهیم
- نوع فونت
- اندازه فونت
- چیز های معمولی مثل رنگ , ضخامت , نوع خط و ...
lineType = cv.LINE_AAپیشنهاد میشود.
font = cv.FONT_HERSHEY_SIMPLEX
cv.putText(img,'OpenCV',(10,500), font, 4,(255,255,255),2,cv.LINE_AA)
اهداف
- هندل کردن ایونت های موس
- یادگیری تابع
cv.setMouseCallback()
یک نمونه ساده
برنامه ای منویسیم که هنگام دوبار کلیک کردن یک دایره روی عکس بکشد
اول یک callback function برای موس ایجاد میکنیم که هنگامی که ایونت موس ایجاد میشود عمل میکند
ایونت موس هر چیزی مثل کلیک چپ و کلیک راست و .... میتواند باشد
یک مختصات (x,y) به ازای هر ایونت دریافت میکنیم
با داشتن این مختصات و تابع میتوانیم هرکاری بکنیم
یک نمونه ساده کد در مثال زیر آمده
import cv2 as cv
events = [i for i in dir(cv) if 'EVENT' in i]
print( events )```
ساخت `callback function` یک قاعده ثابتی دارد که در همه جا قابل اجراست
یک نمونه کد :
```python
import numpy as np
import cv2 as cv
# mouse callback function
def draw_circle(event,x,y,flags,param):
if event == cv.EVENT_LBUTTONDBLCLK:
cv.circle(img,(x,y),100,(255,0,0),-1)
# Create a black image, a window and bind the function to window
img = np.zeros((512,512,3), np.uint8)
cv.namedWindow('image')
cv.setMouseCallback('image',draw_circle)
while(1):
cv.imshow('image',img)
if cv.waitKey(20) & 0xFF == 27:
break
cv.destroyAllWindows()
اکنون میرویم سراغ یک کد پیچیده تر میخواهیم یک مستطیل یا دایره را روی حرکت موس رسم کنیم
import numpy as np
import cv2 as cv
drawing = False # true if mouse is pressed
mode = True # if True, draw rectangle. Press 'm' to toggle to curve
ix,iy = -1,-1
# mouse callback function
def draw_circle(event,x,y,flags,param):
global ix,iy,drawing,mode
if event == cv.EVENT_LBUTTONDOWN:
drawing = True
ix,iy = x,y
elif event == cv.EVENT_MOUSEMOVE:
if drawing == True:
if mode == True:
cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv.circle(img,(x,y),5,(0,0,255),-1)
elif event == cv.EVENT_LBUTTONUP:
drawing = False
if mode == True:
cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv.circle(img,(x,y),5,(0,0,255),-1)
اکنون باید یک callback function و سیستمی برای تغییر حالت بین مستطیل و دایره ایجاد کنیم
img = np.zeros((512,512,3), np.uint8)
cv.namedWindow('image')
cv.setMouseCallback('image',draw_circle)
while(1):
cv.imshow('image',img)
k = cv.waitKey(1) & 0xFF
if k == ord('m'):
mode = not mode
elif k == 27:
break
cv.destroyAllWindows()
اهداف
- یادگیری کار با نوار های لغزنده (trackbar)
- کار با
cv.getTrackbarPos()وcv.createTrackbar()
نمونه کد
اینجا میخوایم یه برنامه ساده بسازیم تا با استفاده از نوار لغزنده و سه عمل RGB رنگ تولید کنیم
تابع cv.createTrackbar() یک نوار لغزنده میسازد و چهار ورودی میگیرد
اولین ورودی : نام نوار لغزنده
دومین ورودی : نام پنجره ای که نوار به آن وصل میشود
سومین ورودی : مقدار پبش فرض
چهارمین ورودی : بیشترین مقدار
پنحمین ورودی : تابع callback که تغییرات لحظه به لحظه ما در نوار را روی صفحه نشان میدهد.
ما در کتابخانه opencv دکمه نداریم برای همین اینجا از نوار لغزنده به عنوان سوییچ استفاده میکنیم که بتوانیم صفحه رو کنترل کنیم
import numpy as np
import cv2 as cv
def nothing(x):
pass
# Create a black image, a window
img = np.zeros((300,512,3), np.uint8)
cv.namedWindow('image')
# create trackbars for color change
cv.createTrackbar('R','image',0,255,nothing)
cv.createTrackbar('G','image',0,255,nothing)
cv.createTrackbar('B','image',0,255,nothing)
# create switch for ON/OFF functionality
switch = '0 : OFF \n1 : ON'
cv.createTrackbar(switch, 'image',0,1,nothing)
while(1):
cv.imshow('image',img)
k = cv.waitKey(1) & 0xFF
if k == 27:
break
# get current positions of four trackbars
r = cv.getTrackbarPos('R','image')
g = cv.getTrackbarPos('G','image')
b = cv.getTrackbarPos('B','image')
s = cv.getTrackbarPos(switch,'image')
if s == 0:
img[:] = 0
else:
img[:] = [b,g,r]
cv.destroyAllWindows()
توضیحات
ابتدا با numpy یک بلوک سه کاناله ساختیم
img = np.zeros((300,512,3), np.uint8)
cv.namedWindow('image')
سپس سه نوار با اسم های R و G و B ساختیم که مقادیر بین 0 و 255 دارند
از تابع nothing به عنوان callback استفاده کردیم
cv.createTrackbar('R','image',0,255,nothing)
cv.createTrackbar('G','image',0,255,nothing)
cv.createTrackbar('B','image',0,255,nothing)
سپس یک سوییچ ساختیم با مقادیر 0 یا 1 که بتوانیم صفحه رو کنترل کنیم
switch = '0 : OFF \n1 : ON'
cv.createTrackbar(switch, 'image',0,1,nothing)
حلقه اصلی برنامه که یک حلقه بینهایت است و اگر کلید 27 یا همان esc فشرده شود برنامه تمام میشود
while(1):
cv.imshow('image',img)
k = cv.waitKey(1) & 0xFF
if k == 27:
break
این قسمت مقادیر را هر لحظه دریافت میکند
r = cv.getTrackbarPos('R','image')
g = cv.getTrackbarPos('G','image')
b = cv.getTrackbarPos('B','image')
s = cv.getTrackbarPos(switch,'image')
سپس وضعیت سوییچ برسی میشود و رنگ صفحه به روزرسانی میشود
if s == 0:
img[:] = 0
else:
img[:] = [b,g,r]
و در نهیات با استفاده از cv.destroyAllWindows() بعد از فشرده شدن Esc پنجره بسته میشود.
اهداف
- دسترسی به پیکسل های عکس و ویرایش آنها
- دسترسی به تنظیمات عکس
- جداسازی و ترکیب عکس ها
- تنظیم ناحیه علاقه
اکثر کد های این قسمت numpy هستند و دانش مناسب شما ازاین کتابخانه میتونه به بهینه سازی کد شما کمک کنه.
دسترسی و تغییر دادن پیکسل
>>> import numpy as np
>>> import cv2 as cv
>>> img = cv.imread('messi5.jpg')
>>> assert img is not None, "file could not be read, check with os.path.exists()"
شما میتوانید با استفاده از سطر و ستون یک پیکسل به اون دسترسی داشته باشید برای RGB یک ارایه به ما برگردونده میشه.
>>> px = img[100,100]
>>> print( px )
[157 166 200]
# accessing only blue pixel
>>> blue = img[100,100,0]
>>> print( blue )
157
همینطوری هم میتوند مغادیر پیکسل رو ویرایش کنید
>>> img[100,100] = [255,255,255]
>>> print( img[100,100] )
[255 255 255]
دسترسی به تنظیمات عکس
تنظیمات عکس شامل تعداد سطر و ستون های عکس , تعداد کانال های یک عکس و تعداد پیکسل و .... میشه.
img.shape یک عکس یک تاپل شامل تعداد سطر و ستون و کانال های عکس میشه
- نکته : در عکس های سفید سیاه تاپل برگردانده شده برای تنظیمات فقط شامل سطر و ستون میشه , این روش خوبی برای تشخیص عکس سفید سیاه از رنگی است.
تعداد کل پیکسل ها با دستور img.size قابل دسترسی است
>>> print( img.size )
562248
datatype یک عکس با دستور img.dtype قابل دسترسی است
>>> print( img.dtype )
uint8
ناحیه مورد علاقه
در مبحث تشخیص اشیا در عکس به عنوان مثال چشم انسان , ابتدا صورت پیدا میشود و سپس در ناحیه صورت به دنبال چشم میگردیم این یکی از کاربرد های ناحیه علاقه است. در اصل به جای گشتن کل عکس , ناحیه کوچک تری را میگردیم که باعث سریع تر شدن فرایند میشود. در مثال زیر توپ رو کپی میکنم
>>> ball = img[280:340, 330:390]
>>> img[273:333, 100:160] = ball

جداسازی و ترکیب کانال های عکس
در بعضی مواقع ممکن است نیاز باشه به صورت جداگانه روی کانال های آبی سبز و قرمز کار کنیم در اینجوری مواقع از دستور زیر برای جداسازی کانال ها استفاده میکنیم در بعضی مواقع هم شاید نیاز باشه کانال هایی رو ترکیب کنیم
>>> b,g,r = cv.split(img)
>>> img = cv.merge((b,g,r))
با دستور اولی جدا سازی انجام میشه و با دستور دومی ترکیب
یا
>>> b = img[:,:,0]
فرض کنید میخواهیم همه پیکسل های قرمز رو به صفر تغییر دهیم
>>> img[:,:,2] = 0
- توجه کنید دستور
cv.split()زمان زیادی برای اجرا نیاز داره , بهتره فقط درموارد ضروری استفاده بشه
ساخت قاب برای عکس
برای ساخت قاب اطراف عکس از دستور cv.copyMakeBorder() استفاده میشه
این تابع ورودی های زیر را میگیرد:
src : عکس ورودی
top, bottom, left, right - عرض حاشیه برحسب پیکسل در جهات گفته شده
borderType - علامتی برای تعریف نوع قاب و میتونه مغادیر زیر رو داشته باشه
cv.BORDER_CONSTANT- با یک رنگ ثابت قاب رو میسازهcv.BORDER_REFLECT- قاب انعکاس عناصر قاب خواهد بود مانند : fedcba|abcdefgh|hgfedcbcv.BORDER_REFLECT_101 or cv.BORDER_DEFAULT- مثل بالا اما با یک تغییر جزیی : gfedcb|abcdefgh|gfedcbacv.BORDER_REPLICATE- عنصر آخر در سراسر قاب تکرار میشه : aaaaaa|abcdefgh|hhhhhhhcv.BORDER_WRAP- نمیشه توضیح داد , یه همچین چیزی میشه : cdefgh|abcdefgh|abcdefg
value : رنگ قاب اگر نوع قاب cv.BORDER_CONSTANT باشد
کد زیر یک مثال از همه انواع قاب های گفته شده هست
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
BLUE = [255,0,0]
img1 = cv.imread('opencv-logo.png')
assert img1 is not None, "file could not be read, check with os.path.exists()"
replicate = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REPLICATE)
reflect = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REFLECT)
reflect101 = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REFLECT_101)
wrap = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_WRAP)
constant= cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_CONSTANT,value=BLUE)
plt.subplot(231),plt.imshow(img1,'gray'),plt.title('ORIGINAL')
plt.subplot(232),plt.imshow(replicate,'gray'),plt.title('REPLICATE')
plt.subplot(233),plt.imshow(reflect,'gray'),plt.title('REFLECT')
plt.subplot(234),plt.imshow(reflect101,'gray'),plt.title('REFLECT_101')
plt.subplot(235),plt.imshow(wrap,'gray'),plt.title('WRAP')
plt.subplot(236),plt.imshow(constant,'gray'),plt.title('CONSTANT')
plt.show()

هدف
- یادگرفتن عملیات های محاسباتی مانند اضافه کردن و کم کردن
- یادگیری توابع
cv.add(), cv.addWeighted()
اضافه کردن
شما میتونید دو عکس رو با تابع cv.add() به هم اضافه کنید یا به صورت ساده تر
توسط کتابخانه numpy , res = img1 + img2 توجه کنید دو عکس باید هم نوع و عمق یکسانی داشته باشند یا تصویر دوم فقط یک مقدار اسکالر باشد
به عنوان مثال
>>> x = np.uint8([250])
>>> y = np.uint8([10])
>>> print( cv.add(x,y) ) # 250+10 = 260 => 255
[[255]]
>>> print( x+y ) # 250+10 = 260 % 256 = 4
[4]
توجه کنید که استفاده از توابع خود کتابخانه نتیجه بهتری به ما میدهند
Image Blending
این نیز ترکیب دوعکس است با این تفاوت که وزن به هر عکس داده میشود که باعت ترکیب شدن بهتر میشود و حس شفافیت بهتری دارد
معادله آن : dst = α⋅img1 + β⋅img2 + γ
α- وزن تصویر اولβ- وزن تصویر دومγ- یک مقدار ثابت
توجه داشته باشید که جمع دو وزن باید 1 شود
مثال زیر از یک ترکیب دوعکس با وزن 0.7 و 0.3 است و سپس تابع cv.addWeighted() معادله را در آن اعمال میکند
در این مثال γ صفر داده شده
img1 = cv.imread('ml.png')
img2 = cv.imread('opencv-logo.png')
assert img1 is not None, "file could not be read, check with os.path.exists()"
assert img2 is not None, "file could not be read, check with os.path.exists()"
dst = cv.addWeighted(img1,0.7,img2,0.3,0)
cv.imshow('dst',dst)
cv.waitKey(0)
cv.destroyAllWindows()

عملیات های بیتی
شامل عملیات بیتی AND، OR، NOT، و XOR میشود این عملیات برای استخراج های بخش های عکس بسیار مفید خواهد بود مانند نواحی مورد علاقه(ROI) غیر مستطیلی در مثال زیر خواهیم دید چگونه یک قسمت خاصی از عکس رو تغییر بدیم
میخواهیم یک لوگو رو روی عکس قرار بدیم , نمیتونیم دو عکس رو به هم اضافه کنیم چون رنگ تغییر میکنه ترکیب هم نمیتونیم بکنیم چون یک حالت شفاف به ما میده و من میخواهیم لوگو مات باشه , برای همین از عملیات های بیتی استفاده میکنم
# Load two images
img1 = cv.imread('messi5.jpg')
img2 = cv.imread('opencv-logo-white.png')
assert img1 is not None, "file could not be read, check with os.path.exists()"
assert img2 is not None, "file could not be read, check with os.path.exists()"
# I want to put logo on top-left corner, So I create a ROI
rows,cols,channels = img2.shape
roi = img1[0:rows, 0:cols]
# Now create a mask of logo and create its inverse mask also
img2gray = cv.cvtColor(img2,cv.COLOR_BGR2GRAY)
ret, mask = cv.threshold(img2gray, 10, 255, cv.THRESH_BINARY)
mask_inv = cv.bitwise_not(mask)
# Now black-out the area of logo in ROI
img1_bg = cv.bitwise_and(roi,roi,mask = mask_inv)
# Take only region of logo from logo image.
img2_fg = cv.bitwise_and(img2,img2,mask = mask)
# Put logo in ROI and modify the main image
dst = cv.add(img1_bg,img2_fg)
img1[0:rows, 0:cols ] = dst
cv.imshow('res',img1)
cv.waitKey(0)
cv.destroyAllWindows()
در قسمت چپ عکس زیر ماسکی است که ساختیم و عکس سمت راست نتیجه رو نشون میده

برای تمرین میتونید که اسلاید شو بسازید که عکس ها خیلی نرم تغییر میکنند
اهداف
در پردازش تصویر چون با عملیات های زیادی در ثانیه کار داریم باید کد ما درست باشد و بهترین راه حل باشد در این قسمت یاد میگیریم :
- چطوری عملکرد کد رو اندازه بگیریم
- چند تا نکته برای بهبود عملکرد
با توابع cv.getTickCount، cv.getTickFrequency آشنا میشیم
و ماژول profile کمک میکنه گزارش دقیقی از کد بدست بیاریم
اندازه گیری عملکرد
تابع cv.getTickCount تعداد سیکلهای کلاک بعد از یک رویداد مرجع (مثل زمانی که کامپیوتر روشن میشود) تا لحظهای که این تابع فراخوانی شده را برمیگردونه.
برای همین اگه قبل و بعد از یک اجرای تابع صداش بزنیم میتونیم تعداد سیکل های کلاک مصرف شده رو به دست بیاریم
نمونه استفاده :
e1 = cv.getTickCount()
# اجرای کد شما
e2 = cv.getTickCount()
time = (e2 - e1) / cv.getTickFrequency()
ما این را با مثال زیر نشان میدهیم. در این مثال، فیلتر میانگینگیری را با هستههایی از اندازههای فرد از ۵ تا ۴۹ اعمال میکنیم. (نگران اینکه نتیجه چگونه به نظر میرسه نباشید هدف چیز دیگه ای هست)
img1 = cv.imread('messi5.jpg')
assert img1 is not None, "فایل خوانده نشد، با os.path.exists() بررسی کنید"
e1 = cv.getTickCount()
for i in range(5, 49, 2):
img1 = cv.medianBlur(img1, i)
e2 = cv.getTickCount()
t = (e2 - e1) / cv.getTickFrequency()
print(t)
# نتیجهای که من گرفتم: 0.521107655 ثانیه
توجه کنید که شما میتونید از تابع time.time() استفاده کنید و درآخر دو مقدار رو از هم کم کنید
بهینهسازی پیشفرض در OpenCV
بسیاری از توابع OpenCV با استفاده از SSE2، AVX و غیر بهینه هستن
این کتابخونه کد های غیر بهینه هم داره و به طور پیشفرض کتابخونه از کد های بهینه استفاده میکنه
اما شما میتونید با دستور cv.setUseOptimized() این موضوع رو برسی کنید
# بررسی فعال بودن بهینهسازی
In [5]: cv.useOptimized()
Out[5]: True
In [6]: %timeit res = cv.medianBlur(img,49)
10 loops, best of 3: 34.9 ms per loop
# غیرفعال کردن بهینهسازی
In [7]: cv.setUseOptimized(False)
In [8]: cv.useOptimized()
Out[8]: False
In [9]: %timeit res = cv.medianBlur(img,49)
10 loops, best of 3: 64.1 ms per loop
درم ثال بالا می بینید که در حالت بهینه شده عملکرد کد دوبرابر بهتر شده اگر سورس کد رو نگاه کنید متوجه میشوید که فیلتر SIMD بهینه شده
اندازهگیری عملکرد در IPython
بعضی مواقع شاید بخویاد عملکرد دو کد مشابه رو برسی کنید , در این موارد در IPython میتونید از دستور timeit استفاده کنید این دستور رو چند بار اجرا کنید تا نتیجه دقیقی بدست بیارید
به عنوان مثال کدوم عملیات بهتره؟
x = 5; y = x**2 یا x = 5; y = x*x یا x = np.uint8([5]); y = x*x یا y = np.square(x)
با استفاده از timeit در محیط IPython پاسخ آن را پیدا میکنیم
In [10]: x = 5
In [11]: %timeit y = x**2
10000000 loops, best of 3: 73 ns per loop
In [12]: %timeit y = x*x
10000000 loops, best of 3: 58.3 ns per loop
In [15]: z = np.uint8([5])
In [17]: %timeit y = z*z
1000000 loops, best of 3: 1.25 us per loop
In [19]: %timeit y = np.square(z)
1000000 loops, best of 3: 1.16 us per loop
میبینیم که دستور x = 5 ; y = x*x سریعترین است و تقریبا 20 برابر سریع تر از Numpy است
اگه دستور ایجاد ارایه رو در نظر بگیریم ممکنه تا 100 برابر سریع تر باشهNumpy
(توسعهدهندگان Numpy روی این مشکل کار میکنند)
- توجه عملیاتهای اسکالر در پایتون سریعتر از عملیاتهای اسکالر در Numpy هستند. بنابراین برای عملیاتهایی که شامل یک یا دو عنصر هستند، اسکالر پایتون بهتر است. Numpy در زمانی که اندازه آرایه کمی بزرگتر باشد مزیت دارد.
یه مثال دیگه
عملکرد دو کد cv.countNonZero() و np.count_nonzero() رو برسی میکنیم
In [35]: %timeit z = cv.countNonZero(img)
100000 loops, best of 3: 15.8 us per loop
In [36]: %timeit z = np.count_nonzero(img)
1000 loops, best of 3: 370 us per loop
همانطور که میبینید، تابع OpenCV تقریباً ۲۵ برابر سریعتر از تابع Numpy است.
- توجه توابع opencv معمولا از Numpy سریع تر هستن برای همین معمولا از توابع خود کتابخونه استفاده کنیم بهتره مگر در موارد خاص
تکنیکهای بهینهسازی عملکرد
- الگوریتم کد رو تا حد ممکن برداری کنید چون Numpy و OpenCV برای عملیاتهای برداری بهینه شدهاند
- از حافظه آشکار استفاده کنید
- تا زمانی که لازم نیست، از کپی کردن آرایهها خودداری کنید. به جای آن سعی کنید از viewها استفاده کنید. کپی کردن آرایه یک عملیات پرهزینه اند
- اگر پس از انجام همه این کارها، کد شما هنوز کند است یا استفاده نکردن از حلقه ها ممکن نیست , از cpython استفاده کنید
هدف
درا ین قسمت یاد میگیریم یه عکس رو چطوری از یک فضای رنگی به یک فضای رنگی دیگه ببریم مثل : RGB -> HSV,....
بیشتر از 150 تا روش برای تبدیل فضاهای رنگی در این کتابخونه وجود داره و ما 2 موردش رو برسی میکنیم تبدیل BGR به Gray و BGR به HSV
برای تبدیل رنگ، ما از تابع cv.cvtColor(input_image, flag) استفاده میکنیم که در آن flag نوع تبدیل رو مشخص میکنه.
- برای تبدیل BGR به Gray، از پرچم
cv.COLOR_BGR2GRAYاستفاده میکنیم. - برای تبدیل BGR به HSV، از پرچم
cv.COLOR_BGR2HSVاستفاده میکنیم.
بقیه پرجم ها(flag) توسط اینطوری میتونید پیدا کنید:
import cv2 as cv
flags = [i for i in dir(cv) if i.startswith('COLOR_')]
print(flags)
نکته: برای HSV، محدودهی Hue بین [0,179]، Saturation بین [0,255] و Value بین [0,255] است. نرمافزارهای مختلف ممکن است از مقیاسهای متفاوتی استفاده کنند، بنابراین اگر میخواهید مقادیر OpenCV را با آنها مقایسه کنید، باید این مقادیر را نرمالسازی کنید.
ردیابی شیء
حالا که تونستیم RGB رو به HSV تبدیل کنیم میتونیم از این روش برای استخراج یک شی استفاده کنیم در فضای HSV نمایش یک رنگ نسبت به BGR راحت تره . الان میخوایم یک شی آبی رنگ رو استخراج کنیم
روش کار :
هر فریم از ویدیو را بگیرید. فریم را از BGR به فضای رنگی HSV تبدیل کنید. تصویر HSV را برای یک محدوده رنگ آبی آستانهگذاری کنید. حالا شیء آبی را به تنهایی استخراج کنید، میتوانیم هر کاری با آن تصویر انجام دهیم.
import cv2 as cv
import numpy as np
cap = cv.VideoCapture(0)
while(1):
# هر فریم را بگیرید
_, frame = cap.read()
# تبدیل BGR به HSV
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
# تعریف محدوده رنگ آبی در HSV
lower_blue = np.array([110, 50, 50])
upper_blue = np.array([130, 255, 255])
# آستانهگذاری تصویر HSV برای دریافت فقط رنگهای آبی
mask = cv.inRange(hsv, lower_blue, upper_blue)
# انجام عمل AND بیتوار بین ماسک و تصویر اصلی
res = cv.bitwise_and(frame, frame, mask=mask)
cv.imshow('frame', frame)
cv.imshow('mask', mask)
cv.imshow('res', res)
k = cv.waitKey(5) & 0xFF
if k == 27: # برای خروج از حلقه، دکمه Escape را فشار دهید
break
cv.destroyAllWindows()
نتیجه کار :

نکته : در تصویر ممکنه مقداری نویز ببینید که این مشکل در فصل های بعدی حل میشه این روش ساده ترین روش استخراج اشیا هست
چگونه مقادیر HSV برای ردیابی را پیدا کنیم؟
این یک سوال بسیار رایجه شما میتونید از تابع cv.cvtColor() استفاده کنید
به جای دادن تصویر فقط مقادیر رنگ تصویر رو بدیم و بعد تبدیل به HSV کنیم
نمونه :
green = np.uint8([[[0, 255, 0]]])
hsv_green = cv.cvtColor(green, cv.COLOR_BGR2HSV)
print(hsv_green)
اکنون میتوانید [H-10, 100, 100] و [H+10, 255, 255] را به عنوان حد پایین و حد بالای خود انتخاب کنید.
توضیحات اضافه
در این کد، از چند تابع مهم OpenCV برای پردازش تصویر و ردیابی اشیاء استفاده شده است. بگذارید هر یک از این توابع را مختصراً بررسی کنیم:
cv.VideoCapture(0):
این تابع برای شروع ضبط ویدیو از دوربین استفاده میشود. عدد 0 به دوربین پیشفرض سیستم اشاره دارد، و اگر شما دوربین دیگری دارید، میتوانید این عدد را تغییر دهید.
cap.read():
این تابع یک فریم از ویدیو را میخواند. نتیجه آن یک لیست شامل دو مقدار است: یک بولین که نشان میدهد آیا خواندن فریم موفق بوده یا نه، و خود فریم تصویر.
cv.cvtColor(frame, cv.COLOR_BGR2HSV):
با استفاده از این تابع، تصویر را از فضای رنگی BGR به HSV تبدیل میکنیم. این تبدیل به ما کمک میکند تا رنگها را راحتتر در فضای HSV شناسایی کنیم.
np.array([lower_blue]) و np.array([upper_blue]):
این خطوط برای تعریف محدوده رنگ آبی استفاده میشوند. lower_blue و upper_blue به ترتیب نشاندهنده حداقل و حداکثر رنگ آبی در فضای HSV هستند.
cv.inRange(hsv, lower_blue, upper_blue):
این تابع آستانهگذاری تصویر HSV را انجام میدهد و یک ماسک باینری تولید میکند. در این ماسک، مقادیر رنگی در محدوده تعیینشده (رنگ آبی) به ۱ و بقیه مقادیر به ۰ تبدیل میشوند.
cv.bitwise_and(frame, frame, mask=mask):
این تابع برای اعمال عملیات AND بیتوار بین تصویر اصلی و ماسک استفاده میشود. با این کار، فقط بخشهایی از تصویر که رنگ آبی دارند (بر اساس ماسک) در خروجی نشان داده میشوند.
cv.imshow('frame', frame):
با استفاده از این تابع، تصویر اصلی را نمایش میدهیم. نام پنجره 'frame' است و این نام به ما کمک میکند تا پنجرهها را شناسایی کنیم.
cv.imshow('mask', mask):
این تابع برای نمایش ماسک باینری تولید شده استفاده میشود که فقط رنگهای آبی را نشان میدهد.
cv.imshow('res', res):
این تابع برای نمایش تصویر نهایی (خروجی) که تنها شامل رنگ آبی است، استفاده میشود.
cv.waitKey(5):
این تابع به مدت ۵ میلیثانیه منتظر میماند تا یک کلید فشرده شود. اگر کلید Escape (کد ۲۷) فشرده شود، حلقه متوقف میشود.
cv.destroyAllWindows():
این تابع برای بستن تمامی پنجرههای بازشده OpenCV استفاده میشود.
بهطور خلاصه، این توابع به ما این امکان را میدهند که تصاویر و ویدیوها را بخوانیم، فضای رنگی را تغییر دهیم و اشیاء رنگی را ردیابی کنیم. این یک رویکرد ساده و کارآمد برای پردازش تصویر است!